This discusses running a sane variety of Linux ‘container’ under SGE. It covers the simple single-node case but also running multi-node MPI. The latter isn’t as straightforward as the propaganda suggests.
Container Sanity, and Otherwise
“I want to run Docker containers under SGE.” No, you don’t — really; or at least your clued-up system manager doesn’t want that. It just isn’t sane on an HPC system, or probably more generally under resource managers similar to SGE. (That said, see bdocker.)
The short story is that (at least currently) Docker uses a privileged system daemon, through which all interaction happens, and using it is essentially equivalent to having root on the system. Other systems, like rkt, at least make that explicit, e.g. starting the containers from systemd. Apart from security issues, consider the implications for launching, controlling, and monitoring containers[1] compared with just exec’ing a program as normal in an appropriate resource allocation, especially if distributed parallel execution is involved.
Apart from requiring privileges, most ‘container’ systems at least
default to a degree of isolation inappropriate for HPC, and may have
other operating constraints (e.g. running systemd ☹). What we really
want is the moral equivalent of secure, unprivileged chrooting to an
arbitrary root, with relevant filesystem components and other
resources visible.
Fortunately that exists. In addition to the following, see the
userspace alternatives below.
The initial efforts along those lines were NERSC’s
CHOS and
Shifter
which require particular system configuration support, providing a
limited set of options to run.[2] Now
Singularity provides the chroot-y
mechanism we want, though the documentation doesn’t put it like that.
It allows executing user-prepared container images as normal exec’ed
user processes.[3]
As an example, our RHEL6-ish system doesn’t have an OS package of
Julia, but has a julia executable which is a Debian container with
julia as the entry point. It’s usually easy enough to build such a
container from scratch, but if you insist on using a Docker one —
which doesn’t start services, at least — you can convert it to the
Singularity format reasonably faithfully. The Julia example actually
was generated (with a running docker daemon) using
sudo singularity import -t docker -f julia /usr/local/bin/julia
Singularity Version
Note that the examples here use the 2.x branch of the Singularity
fork from https://github.com/loveshack/singularity.
It’s an older version than the latest at the time of writing, but with
a collection of fixes (including for security) and enhancements
relevant to this discussion (such as using $TMPDIR rather than
/tmp) which unfortunately aren’t acceptable ‘upstream’. There are
rpms in the Fedora/EPEL testing repos at the time of writing. Also,
this assumes an RHEL6-like system as a reasonable lowest level of
Linux features likely to be found in current HPC systems; newer
kernels may allow other things to work. If you run Debian, SuSE, or
another distribution, that’s probably perfectly fine, but you’ll need
to translate references to package names, in particular. Of course,
Singularity is Linux-specific and I don’t know whether any of this
would carry over to, say, varieties of BSD or SunOS.
Running in SGE
Let’s turn to SGE specifics. Beware that this isn’t perfect; there are rough edges, particularly concerning what the container inherits from the host, but it’s usable with some fiddling. It demonstrates that how the portability (and reproducibility, to some extent) claimed for containers is really a myth in a general HPC context, if that isn’t obvious.[4]
Single-node
Since Singularity containers are executable, in simple cases like the
julia one, with an appropriately-defined container entry point, you
can just run them under SGE like normal programs if the Singularity
runtime is installed on the execution host.[5]
You can run things inside them other than via the entry point:
qsub -b y singularity exec $(which julia)command args …
Alternatively, we can avoid explicit mention of the container by
specifying the shell SGE uses to start jobs, assuming the container
has the shell as the entrypoint. That can be done by linking
/bin/sh to /singularity (the execution entrypoint) in the
container, either while building it or subsequently:
echo 'ln -sf /bin/sh /singularity' | singularity mountcontainer/mnt
Then we can use
qsub-b y -Scontainer … command
so that the shepherd launches container -c command. Using the
container as a shell with SGE is the key to the method of running MPI
programs from containers below. The -S could be derived from a
dummy resource request by a JSV, or you can put it in a .sge_request
in a working directory and see, for example
$ cat x.o$(qsub -cwd -terse -sync y -b y -N x lsb_release -d) Description: Scientific Linux release 6.8 (Carbon) $ cd debian $ cat x.o$(qsub -cwd -terse -sync y -b y -N x lsb_release -d) Description: Debian GNU/Linux 8.6 (jessie)
after doing (for a container called debian.img)
cd debian; echo "-S $(pwd)/debian.img" > .sge_request
Distributed MPI
That’s for serial — or at least non-distributed — cases. The distributed parallel environment case is more complicated. This is confined to MPI, but presumably other distributed systems with SGE tight integration would be similar.
There are clearly two ways to operate:
-
Execute
mpirun[6] outside the container, i.e. use the host’s launcher, treating the container as a normal executable; -
Run it from within the container, i.e. the container’s installation of it.
Host-launched
If the container has an MPI installation that is compatible with the
host’s — which in the case of Open MPI typically means just the same
version — then you can probably run it as normal under
mpirun, at least if you have the components necessary to
use the MPI fabric in the container, including device libraries like
libmlx4. MPI Compatibility is necessary because the library inside
the container has to communicate with the orted process outside it
in this mode.
Container-launched
Now consider launching within the container. You might think of installing Singularity in it and using something like
qsub -pe…singularity execcontainermpiruncontainer …
but that won’t work. Without privileges you can’t nest Singularity
invocations, since sexec, which launches a container, is setuid and
setuid is disabled inside containers.
However, it is still possible to run a distributed job with an MPI implementation in the container independently of the host’s, similarly to the serial case. It’s trickier with more rough edges, but provides a vaguely portable solution if you can’t dictate the host MPI.
The container must be prepared for this. First, it must have enough
of an SGE installation to run qrsh for launching on the slave nodes.
That means not only having the binary, but also having
SGE_ROOT etc. defined, with necessary shared directories mounted
into it (or the necessary files copied in if you don’t use a shared
SGE_ROOT). In the shared-everything system here using CSP security,
they’re used like this in singularity.conf:
bind path maybe = /opt/sge/default bind path maybe = /var/lib/sgeCA
where the maybe (in the Singularity fork) suppresses warnings for
containers lacking the mount point.[7]
There are two aspects of startup of MPI-related processes inside the
container. The mpirun process is started as the SGE job, which
could involve either supplying the command line as arguments to the
container executable, or invoking singularity exec. When that tries
to start processes on remote hosts with qrsh from inside the
container, we need a hook to start them in the container.
qrsh -inherit doesn’t use the shell — perhaps it should —
but we can use QRSH_WRAPPER instead.
There are two ways of setting this up. We could define a new parallel
environment, but it’s possible to do it simply as a user. Rather than
supplying the mpirun command line as an argument of the container,
we can use qsub's -S switch to invoke the container — if with even
more container preparation. The following diagram shows how it works.
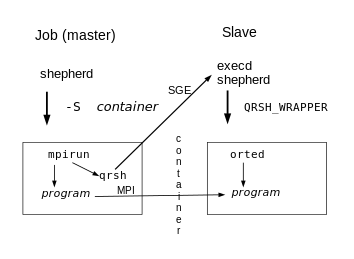
Here’s a demonstration of running an openmpi-1.10 Hello World in a
CentOS 7 container (c7) on Scientific Linux 6 hosts which have
openmpi-1.6 as the system MPI (for historical reasons), where
num_proc arranges two nodes on the heterogeneous system. I haven’t
yet debugged the error message.
$ cat mpirun.o$(qsub -terse -sync y -b y -pe mpi 14 -l num_proc=12 -S ~/c7 mpirun mpi-hello-ompi1.10) Hello, world, I am 1 of 2, (Open MPI v1.10, package: Open MPI mockbuild@ Distribution, ident: 1.10.0, repo rev: v1.10-dev-293-gf694355, Aug 24, 2015, 121) [...] Hello, world, I am 13 of 14, (Open MPI v1.10, package: Open MPI mockbuild@ Distribution, ident: 1.10.0, repo rev: v1.10-dev-293-gf694355, Aug 24, 2015, 121) ERROR : Could not clear loop device /dev/loop0: (16) Device or resource busy
This is the sort of thing you need to install as /singularity in the
container to make that work [download
link].[8] Note that it won’t work the
same for jobs run with qrsh, which doesn’t support -S, so you’d
have to run the container explicitly under singularity and set
QRSH_WRAPPER.
#!/bin/sh
# Set up for MPI. An alternative to get "module" defined is to use
# "/bin/sh -l" if .profile is sane when used non-interactively, or
# to pass module, MODULESHOME, and MODULEPATH in the SGE environment.
. /etc/profile
module add mpi
# Assume submission with qsub -S <this container>; then we need
# QRSH_WRAPPER defined foe starting remote tasks. This wouldn't work if
# SHELL was a real system shell, but we can't check it actually is a
# container since it may not be in our namespace.
QRSH_WRAPPER=${QRSH_WRAPPER:-$SHELL}; export QRSH_WRAPPER
# We might be called as either "<cmd> -c ..." (for job start), or as
# "<cmd> ..." (via qrsh).
case $1 in
-c) exec /bin/sh "$@";;
*) exec $*;;
esacOf course, instead of fixing /singularity like that, you could use two
slightly different shell wrappers around singularity exec for the
shell and QRSH_WRAPPER, which would work for any container in which
you can run /bin/sh, but you’d have to pass the file name of the
container in the environment.
You could think of using a privileged PE start_proc_args to modify
(a copy of?) the container on the fly. That would insert the SGE
directories, /singularity, and, perhaps, a static qrsh; it doesn’t
seem too clean, though.
There shouldn’t be any dependence on the specific MPI implementation
used, providing it is tightly integrated. However, some release of
Open MPI 2 has/will have some undocumented(?) knowledge of Singularity
in the schizo framework. That messes with the search path and the
Singularity session directory for containers it starts. In this case,
neither seems useful. The runtime won’t detect Singularity anyhow if
the container is invoked directly, rather than with
singularity exec, so the session directory will be directly in the
TMPDIR created by tight integration, rather than Open MPI’s
sub-directory chosen by schizo.
Summary
To run MPI programs, the container has to be compatible with the host
setup, either by using a compatible MPI installation and taking
advantage of the host mpirun, by being prepared with support for
running qrsh from within it and a suitable entrypoint to support the
SGE -S and QRSH_WRAPPER used to launch within it, or using shell
wrappers to avoid the entrypoint. Obviously you could use a JSV to
modify the job parameters on the basis of a pseudo-complex,
e.g. -l singularity=debian. As well as setting parameters, the JSV
could do things like checking the container for the right mount
points etc.
I don’t have operational experience to recommend an approach from the various possibilities.
Alternatives
There are potential unprivileged alternatives to container solutions, depending on what the perceived requirement is. There is Guix (or Nix) for running a reproducible environment; they are potentially runnable unprivileged with PRoot, as below.
I haven’t done much that way, but it’s possible to run programs
unprivileged in a chroot-style tree with tools from Debian, as done
by debootstrap, for instance.
The best such tool is probably PRoot.
Presumably system calls with it will be slow as it uses ptrace,
though it seems to have some optimization, may not matter with
computational programs, especially if they do i/o in userspace. See
also the CARE tool with PRoot (but the URL is dead), which does
basically what the initial version of Singularity did. Proot can even
support roots for different architectures via QEMU. (Note the
possible issue with
seccomp, and also that dpkg fails when installing packages into a
Debian PRoot with apt unless SELinux is disabled, but it’s not clear
where the problem lies.)
udocker uses PRoot to run simple
Docker images without privileges.
Otherwise, something like fakechroot or
pseudo,
which use LD_PRELOAD, could be adapted to intercept just the chroot
filesystem, always assuming you have dynamic binaries, but
fakechroot may be good enough asis, e.g. with a link to your home
directory. (pseudo can at least preserve the working directory,
but I’ve had trouble getting the packaged versions working.)
Of these, only fakeroot is in EPEL, but there are packages for
others currently in a
copr repo.
https://images.linuxcontainers.org/images/ is a good source of rootfss
as an alternative to building a root with debootstrap etc.:
$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.3 (Maipo)
$ { wget https://uk.images.linuxcontainers.org/images/ubuntu/xenial/\
> amd64/default/20170504_03:49/rootfs.tar.xz -O - |
> tar Jfx -; } >& /dev/null
$ proot -R . /bin/cat /etc/debian_version
stretch/sid
$ PATH=/bin:/sbin:$PATH proot -S . apt install -y hello >& /dev/null
$ proot -R . hello
Hello, world!
$
As well as Shifter, LLNL’s charliecloud also provides unprivileged execution of Docker images but requires user namespaces. It is compared with Singularity in that report. The released version depends on user namepsaces at the time of writing, but the development version has setuid support.
Addendum: Copyright
Do note that to distribute containers lawfully (unlike many), you must abide by the licences of all the components of the container, which will normally involve providing access to the source and build system for copyleft components — such as at least coreutils and glibc in a typical minimal installation — including for components of SGE in this case. Even BSD-ish licences have requirements to ship the copyright notice.